
Hace ya casi un año que Amazon publicó que estaban desarrollando el soporte de Amazon SQS como «Event Source» para una función Lambda, y desde que la solución estuvo disponible buscaba una escusa para poder encontrar un mini proyecto para probarla.
Para el desarrollo interno de la empresa tengo un «Bot» que obtiene de manera diaria un CSV con alrededor de 1.000.000 de filas. Para todos los que estamos acostumbrados a trabajar con archivos grandes, 1M de datos no suena tan complejo, por lo que a pesar de tener mejores opciones decidí que era el momento de hacer una prueba de fuego parseando este archivo y enviando el resultado directamente a la cola fila por fila para luego ser procesado a través de una función lambda.
Este post es para comentar sobre la estructura final del proyecto, y como se fue modificando para poder funcionar de manera correcta.
Suposiciones
- El archivo ya existe. Este POST no es sobre como crear un BOT para obtener un archivo.
- Existe algo de conocimiento previo de lo que significa SQS, Lambda, un Trigger y Aurora.
Los problemas encontrados
A continuación una lista de problemas encontrados en el orden que fueron sucediendo.
- El parseo inicial fue realizado a través de una función creada en NodeJS. Al parecer hasta el día de hoy el SDK de NodeJS de AWS tiene un bug en el cual el garbage collector no alcanza a borrar suficiente memoria cuando se usan sockets. Esto implica que el enviar cientos de llamados desde NodeJS hacia SQS implicaba que a pesar de tener el máximo de memoria soportado para la ejecusión, el resultado era falla de la ejecución del código. La recomendación de Amazon fue usar otro lenguaje para esta solución.
- Luego los mensajes a SQS fueron enviados desde el parseador desarrollado en PHP sin problemas de manera secuencial, esperando que cada uno de los mensajes se enviara antes de seguir con el siguiente. Si bien esto funcionó sin problemas, el tiempo necesario para que la solución terminara fue de un poco más de 24 horas. ( Cero opción de que esto sea una solución definitiva ).
La Solución
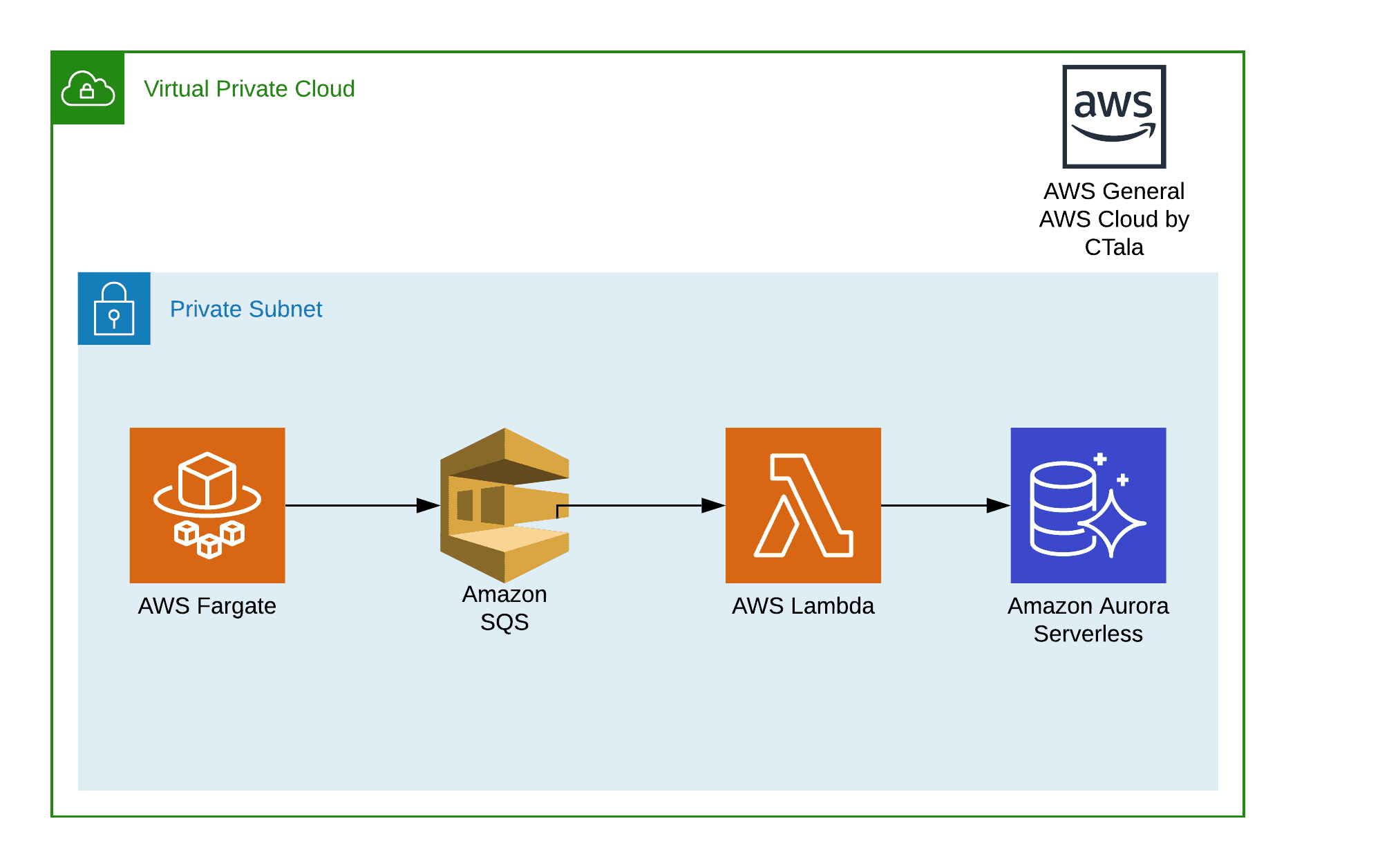
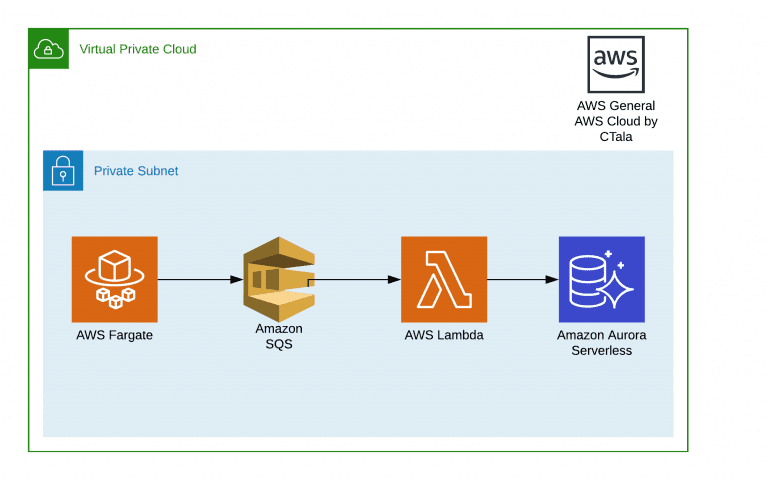
Una de las características que más me gusta del desarrollo en la nube y los microservicios, es la versatilidad de como puedo manejar distintos lenguajes de programación para distintas soluciones y que todos puedan convivir sin problemas entre ellos. El BOT funciona en un contenedor de docker con PHP, y el consumidor de la cola en una función lambda utilizando NodeJS conectado a una base de datos Aurora Serverless.
Envío del mensaje a la cola
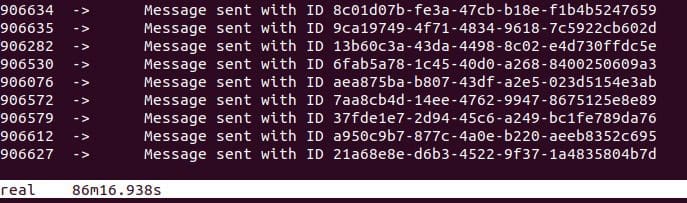
Para reducir el tiempo en que el parser del archivo CSV se utilizó una librería que trae promesas y asincronía a los desarrollos en PHP. La verdad hasta hace un par de días no sabía que esto era posible, pero la librería Guzzle Promises funciona de maravilla. Gracias a esto en vez de procesar los mensajes de la cola de manera individual los comencé a procesar por lotes de 500. Solo este cambio hizo que la solución en vez de demorarse un poco más de 24 horas, solo se demorara 86 minutos.
Si bien para la necesidad que tenía ya era un tiempo razonable, en especial por la hora a la que se ejecuta la solución, comencé a ver un par de alternativas que me permitieran reducir el tiempo de ingreso a la cola.
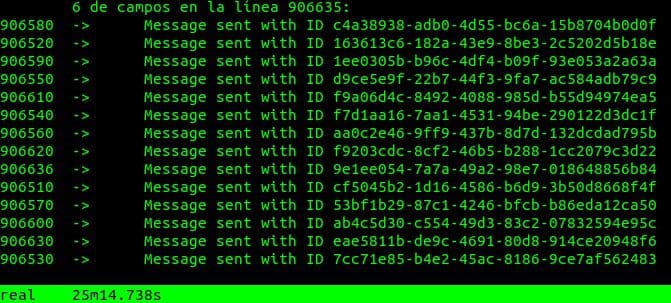
Encontré que en vez de mandar una fila del CSV por mensaje se aprovechaba de mejor manera la inserción en la cola si el mensaje incluía arreglos de 10 filas por mensaje. Solo este cambio significó una mejora desde los 86 minutos a 25 minutos.
A esta altura por el momento ya quedo contento con la solución de inserción a la cola. La verdad es que se puede seguir mejorando la inserción, incluso incluyendo más filas por mensaje y comprimir el texto usando alguna librería. Es muy posible que en un futuro lo haga por curiosidad, pero por el momento me quedo contento con el tiempo de ejecución.
Procesando el mensaje.
Ya pasando por el proceso de inserción a la cola, el resto fue bastante sencillo. En la misma función lambda se ingreso como trigger directamente la cola en dónde se estaban ingresando los mensajes, con un máximo de mensajes por función de 10 ( Esto lo podemos hacer mucho más grande ! ).
Por lo que queda como lo siguiente :
- Cada mensaje contiene 10 filas con datos.
- Cada lambda maneja de manera «simultanea» 10 mensajes de la cola.
- Cada función lambda fue configurada con una concurrencia máxima de 100 para no tener que hacer mayores cambios en las conexiones a la BdD Aurora. Para re-usar las conexiones a la base de datos se usa la librería Aurora Mysql Cluster de NodeJS.
Esto resulta en que en cada unidad de tiempo de procesamiento se pueden estar ingresando a la BdD alrededor de 10000 de lo que en su momento fueron filas con información desde un CSV, por lo tanto, la velocidad de procesamiento e inserción a la base de datos es mucho mayor que la velocidad de inserción en la cola (Lo que podría traducirse en que quizás la mejor solución era ingresar a la base de datos de manera directa y no pasar por SQS).
Conclusión
Puede que la solución no sea la mejor para el problema dado por lo que deberé cambiarla en un futuro cercano. Sin embargo, estoy contento con el resultado del desempeño de Lambda con SQS como event source, que era lo que se quería probar desde un comienzo.
Espero poder probar el trigger desde SQS a Lambda en un proyecto en producción pronto.
