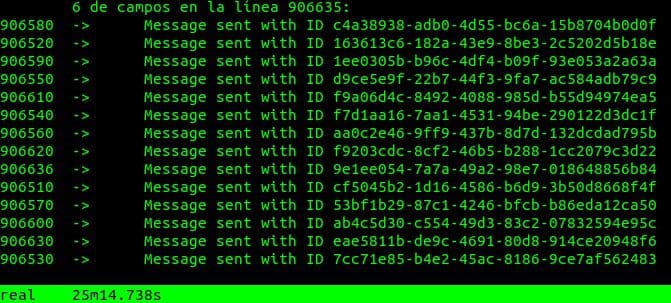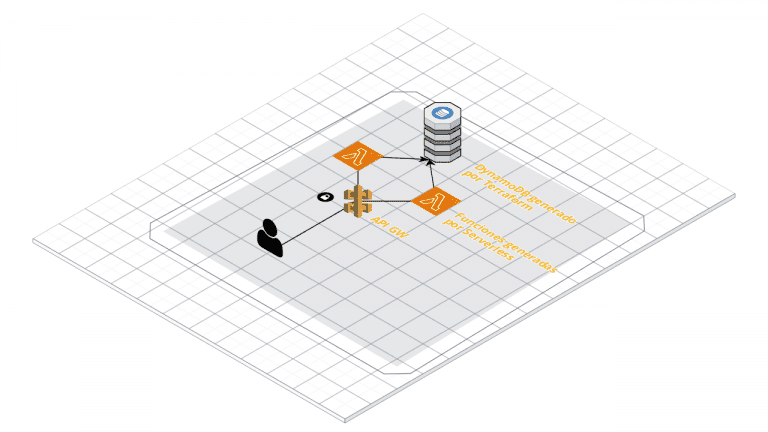
Hace ya algunos años que he querido hacer un tutorial como este, en dónde de manera sencilla pueda explicar los distintos pasos de la creación de un API REST, o al menos como lo he aprendido a hacer basado en experiencia y errores.
Una de las razones del por qué nunca comencé con este proyecto es debido a que crear un API puede ser tan complejo como uno quiera, y nunca encontré el tiempo para realizarlo, por lo que decidí lanzar este tutorial por partes e iré publicando las distintas partes a medida que las vaya realizando.
En este tutorial crearemos un Full RESTfull API con seguridad basada en tokens utilizando AWS, Swagger, Terraform, DynamoDB, SSM, y Serverless Framework quién generará los recursos del API Gateway y Lambdas.
| Estado Proyecto | En Progreso |
| Fecha Inicio | 17/05/2020 |
| Fecha Actualización | 17/05/2020 |
| Fecha de Término | – |
| Capítulos listos | 2/10 |
| Link Youtube Playlist | https://www.youtube.com/playlist?list=PLCjIDwuXOgwR64ScpUf6WLnW6j2jdkREX |
Indice
- Entendiedo la necesidad. API de manejo de datos de usuarios y los datos requeridos.
- Conociendo las herramientas que se utilizarán y el por qué las usaremos.
- Diseñando la API utilizando Swagger. Antes de crear el API debemos saber que información recibirá y que información retornará.
- Generando la base de datos DynamoDB, y el recurso relacionado de SSM utilizando Terraform.
- Generando los endpoints utilizando Serverless Framework.
- Generando el CRUD de la aplicación. – Create, Read, Update, Delete –
- Asegurando nuestra API.
Extra
- Bloqueo de recursos en Terraform para impedir eliminaciones accidentales.
- Endpoint que lista los usuarios con paginación.
- Sincronizando DynamoDB con Redshift para realizar operaciones analiticas.
Contenido
Puedes encontrar el playlist con los vídeos en el siguiente link : https://www.youtube.com/playlist?list=PLCjIDwuXOgwR64ScpUf6WLnW6j2jdkREX
1.- Entendiendo la necesidad.
A pesar de la creencia popular nadie desarrolla por desarrollar, a menos que esté aprendiendo. Es muy importante entender la necesidad que existe por detrás de lo que se está creando para no tener duplicidad en el trabajo realizado ni atrasos inesperados. La solución siempre se debe de diseñar antes del proceso de desarrollo.
2.- Conociendo las herramientas
En este capítulo conversamos un poco de las herramientas que estaremos utilizando para este proyecto.
- Serverless Framework
- Terraform
- Swagger
- API Gateway
- Amazon Lambda
- Amazon DynamoDB
- SSM – Parameter Store.
3.- Diseñando la API (Work in Progress)
4.- Generando los recursos / DynamoDB (Work in Progress)
5.- Generando los endpoints usando Serverless. (Work in Progress)
6.- Generando el CRUD de la aplicación (Work in Progress)
7.- Asegurando el API (Work in Progress)