Aprende a realizar un REST API usando Serverless, Amazon Lambda, Express, Node.js y DynamoDB. Además usaremos un par de herramientas que hará mucho más sencilla su desarrollo.
Source: Deploy a REST API using Serverless, Express and Node.js
Hace un tiempo que me fasciné con la tecnología Serverless, hasta el punto que gran parte de mis desarrollos y sistemas ya están funcionando con ella. Fue a tal nivel que me vi obligado a aprender lenguajes de programación de los cuales nunca me había hecho el tiempo de aprender, en este caso NodeJS ya que nunca me gustó mucho Javascript. Para mi sorpresa ES6, en lo que está basado actualmente la nueva versión de javascript, se adecua un montón a la forma como estoy acostumbrado a programar por lo que el aprendizaje fue más sencillo.
Aprovecho de escribir este tutorial ya que por un lado un amigo – Marcelo A. – me dijo que ya no estoy escribiendo tanto en mi blog, por lo cual he perdido tráfico, además de poder ayudar a otro amigo – Ernesto M.- con una breve introducción de estas tecnologías.
En este ejemplo crearemos una API REST – solo usaremos el create, list, and get como ejemplos- de productos que se conectará a una tabla en DynamoDB. (Pueden ver el código del ejemplo en GitHub)
Si bien a continuación hay una lista de requerimientos que deberías tener para poder entender lo más posible este ejemplo, puedes perfectamente copiar el código desde el repositorio y probarlo directamente. Yo estaré programando directamente en Linux, pero lo que mostraré debería ser transversal.
Requerimientos :
- Tener una cuenta en Amazon Web Services.
- Tener instalado la herramienta de Serverless.
- Tener instalado NodeJS y npm.
- Tener un IDE ( Netbeans, Atom, Sublime, etc ) con el cual poder editar el código de manera adecuada y entendible.
Creando el Proyecto
ExpressJS es un framework de NodeJS que permite el fácil manejo de rutas y endpoints, además de un sin número de funcionalidades en las sesiones y middlewares. En este ejemplo solo lo usaremos de manera sencilla, pero bienvenidos son de poder averiguar todo lo posible, de buscar más ejercicios y ejemplos, y adaptar el conocimiento a sus necesidades.
express --view=pug productos
cd productos && npm install
Con lo anterior creamos un proyecto/carpeta llamado productos, ingresamos a la carpeta e instalamos las dependencias por defecto que trae express. El código generado tiene muchas más de las cosas que necesitamos para este sencillo ejemplo, pero los dejaremos ahí para que puedan jugar en caso de querer probar y ver que hacen. A continuación la estructura que deberíamos tener en este momento sin incluir la subcarpetas de los módulos.
├── app.js
├── bin
│ └── www
├── LICENSE
├── nbproject
│ ├── private
│ ├── project.properties
│ └── project.xml
├── node_modules
├── package.json
├── public
│ ├── images
│ ├── javascripts
│ └── stylesheets
├── README.md
├── routes
│ ├── index.js
│ └── users.js
└── views
├── error.pug
├── index.pug
└── layout.pug
Podemos notar que en la carpeta rutas tenemos una para usuarios y una de index, y podemos corroborar que estas son llamadas desde el archivo app.js.
Si en este momento todo sigue bien, podemos probar que el código inicial funcione de la siguiente manera :
DEBUG=productos:* npm start
Ahora podemos acceder a través de un explorador y veremos la pantalla inicial de express.

Agregando Ruta de Productos
En este momento deberíamos ser capaces de entrar al endpoint de usuarios, pero lo que nosotros queremos es una ruta para los productos. Para lograrlo :
- Copiaremos el archivo de usuarios (users.js) en la misma carpeta con nombre de productos.js
- Agregaremos la variable productos en el archivo app.js de la siguiente manera : var productos = require(‘./routes/productos’);
- Le diremos a express que queremos usar la nueva ruta de productos como su mismo nombre : app.use(‘/productos’, productos);
En archivo de productos.js agregaremos dos métodos, un get y un create.
var express = require('express');
var router = express.Router();
/* GET users listing. */
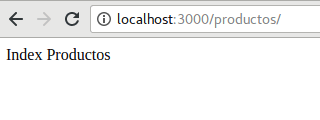
router.get('/', function (req, res, next) {
res.send('Index Productos');
});
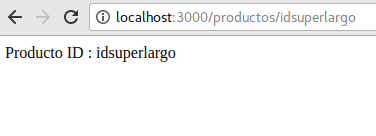
router.get('/:id', function (req, res, next) {
res.send('Producto ID : ' + req.params.id);
});
router.post('/', function (req, res, next) {
res.send('CREANDO PRODUCTO');
});
module.exports = router;
Si iniciamos el servidor nuevamente deberíamos ser capaces de acceder a las rutas de index, de producto, y de creación con los verbos respectivos ( get and post ).
Agregando Serverless
Antes de poder iniciar las conexiones a la BdD con DynamoDB, debemos hacer unos cambios para utilizar la herramienta de serverless. Recuerda que debes de tener el comando serverless instalado.
- Agregamos la librería serverless-http
- Cargamos la librería de serverless-http
Para agregar la librería, abrimos la carpeta del proyecto y ejecutamos :
npm install --save serverless-http
Ahora en el archivo app.js incluimos al comienzo la librería de la siguiente manera :
const serverless = require('serverless-http');
Al final del archivo reemplazamos module.exports = app por module.exports.handler = serverless(app) ya que ahora es serverless quién se encargará de ejecutar el código.
Con estos cambios, solo nos falta decirle a serverless que es lo que debe de hacer, y como se debe de comportar. Esto lo hacemos con un archivo que creamos en el root del directorio llamado serverless.yml con el siguiente contenido.
# serverless.yml
service: api-rest-productos
provider:
name: aws
runtime: nodejs6.10
stage: dev
region: us-east-1
functions:
app:
handler: app.handler
events:
- http: ANY /
- http: 'ANY {proxy+}'
Teniendo ya la configuración de serverless lista, ahora solo nos queda subirlo a Amazon Lambda. Serverless creará a través de CloudFormation todos los recursos que nuestra API pueda llegar a necesitar, para hacer el deploy simplemente ejecutamos el comando sls deploy.
$ sls deploy
Serverless: Packaging service...
Serverless: Excluding development dependencies...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
.....
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service .zip file to S3 (2.73 MB)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
.................................
Serverless: Stack update finished...
Service Information
service: api-rest-productos
stage: dev
region: us-east-1
stack: api-rest-productos-dev
api keys:
None
endpoints:
ANY - https://og6f6nu8b9.execute-api.us-east-1.amazonaws.com/dev
ANY - https://og6f6nu8b9.execute-api.us-east-1.amazonaws.com/dev/{proxy+}
functions:
app: api-rest-productos-dev-app
Serverless: Publish service to Serverless Platform...
Serverless creó la función lambda y el API Gateway correspondiente para poder acceder a ella. En general yo SOLO creo las funciones de esta manera, ya que me gusta poder modificar los API Endpoints desde la consola de Amazon.
En este caso si accedemos a los endpoints que nos da como resultado serverless, podemos acceder a través de la web a los ejemplos que vimos de manera local anteriormente.
Accediendo a DynamoDB
Ya tenemos nuestra aplicación andando sin problemas en los servidores de amazon ( Ojo, que este ejemplo no tiene un servidor asociado! ), ahora la idea sería hacer algo útil con ella.
- Generaremos el nombre de la tabla de manera dinámica.
- Crearemos una tabla de DynamoDB de manera automática dependiendo del Stage en que se encuentre nuestro desarrollo.
- Generaremos los permisos que nuestra aplicación necesita para poder acceder a estos recursos.
Editaremos entonces el archivo serverless.yml para hacer todo lo anterior.
# serverless.yml
service: api-rest-productos
custom:
tableName: 'api-rest-productos-${self:provider.stage}'
dynamodb:
start:
migrate: true
provider:
name: aws
runtime: nodejs6.10
stage: dev
region: us-east-1
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource:
- { "Fn::GetAtt": ["ProductsDynamoDBTable", "Arn" ] }
environment:
PRODUCTS_TABLE: ${self:custom.tableName}
functions:
app:
handler: app.handler
events:
- http: ANY /
- http: 'ANY {proxy+}'
resources:
Resources:
ProductsDynamoDBTable:
Type: 'AWS::DynamoDB::Table'
Properties:
AttributeDefinitions:
-
AttributeName: productId
AttributeType: S
KeySchema:
-
AttributeName: productId
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: ${self:custom.tableName}
Con los cambios, al hacer el deploy se generará la tabla de DynamoDB correspondiente, en este caso terminada con -dev.
Ahora modificaremos nuestra ruta de productos para poder conectar con nuestra nueva tabla.
Primero instalaremos el SDK de Amazon y lo incluiremos en nuestro código.
$ npm install –save aws-sdk
Agregamos la librería de Amazon en nuestro archivo de productos.js después de requerir la librería de express.
const AWS = require('aws-sdk');
Después de las librerías agregamos el siguiente código para poder acceder a las tablas :
const PRODUCTS_TABLE = process.env.PRODUCTS_TABLE;
const dynamoDb = new AWS.DynamoDB.DocumentClient();
Finalmente modificamos nuestro archivo de productos para poder realizar las operaciones con la tabla.
/* GET products listing. */
router.get('/', function (req, res, next) {
var params = {
TableName: PRODUCTS_TABLE
};
dynamoDb.scan(params, function (err, data) {
if (err)
console.log(err, err.stack); // an error occurred
else
console.log(data); // successful response
res.json(data);
});
});
// Get Product endpoint
router.get('/:productId', function (req, res) {
const params = {
TableName: PRODUCTS_TABLE,
Key: {
productId: req.params.productId,
},
}
dynamoDb.get(params, (error, result) => {
if (error) {
console.log(error);
res.status(400).json({error: 'No se pudo obtener el producto'});
}
if (result.Item) {
const {productId, name} = result.Item;
res.json({productId, name});
} else {
res.status(404).json({error: "Producto no encontrado"});
}
});
})
router.post('/', function (req, res, next) {
console.log("Creando Producto");
const {productId, name} = req.body;
console.log("productId = " + productId);
console.log("name = " + name);
if (typeof productId !== 'string') {
res.status(400).json({error: '"productId" must be a string -> ' + productId});
} else if (typeof name !== 'string') {
res.status(400).json({error: '"name" must be a string' + name});
}
const params = {
TableName: PRODUCTS_TABLE,
Item: {
productId: productId,
name: name,
},
};
dynamoDb.put(params, (error) => {
if (error) {
console.log(error);
res.status(400).json({error: 'No se pudo crear producto'});
}
console.log("Producto " + productId + " creado exitosamente.");
res.json({productId, name});
});
});
Ingresando Y obteniendo datos.
Para ingresar los datos podemos hacerlo a través de CURL, generar un formulario, o simplemente usar una herramienta como PostMan.
En este caso ingresemos dos datos para probar (Recuerda cambiar la URL por la tuya !):
curl -H "Content-Type: application/json" -X POST https://og6f6nu8b9.execute-api.us-east-1.amazonaws.com/dev/productos -d '{"productId": "mySku", "name": "Mi Producto"}'
curl -H "Content-Type: application/json" -X POST https://og6f6nu8b9.execute-api.us-east-1.amazonaws.com/dev/productos -d '{"productId": "mySku2", "name": "Mi Producto2"}'
curl -H "Content-Type: application/json" -X POST https://og6f6nu8b9.execute-api.us-east-1.amazonaws.com/dev/productos -d '{"productId": "mySku3", "name": "Mi Producto3"}'
Para ver la lista de los productos ingresados simplemente accedemos al endpoint de productos
Y para ver un producto particular agregamos al endpoint el id, por ejemplo :
Mejoras al Ejemplo.
Claramente este es un ejemplo sencillo de lo que se puede lograr, algunos ejemplos de mejoras con los que podrías jugar :
- Agregar seguridad, o autorización al API. Esto lo puedes hacer directamente en API Gateway o a través de código.
- Usar Clases y Herencias. En este ejemplo no aprovechamos el poder de las clases para hacerlo más sencillo.
- Instalar plugins para poder desarrollar de manera local. El desarrollo es mucho más expedito si lo puedes de hacer local.
- Y lo que se te ocurra!
Finalizando
La combinación de herramientas presentada en este artículo puede ayudarte a tener los conocimientos básicos de la tecnología de funciones como servicio. Queda mucho por leer y aprender, pero de verdad espero que sean tan apasionados como ella como yo. Mucho éxito !
BTW, recuerda ver el código del proyecto en el GitHub : https://github.com/ctala/introduccion-serverless